
How to scramble test data in AWS Aurora

According to AWS Well Architectured Framework, one of the security principles is to keep people away from data. The more you interact with sensitive information - the more the probability of human error. And the impact of real or even potential data misuse is very high, for example, Twitter case in 2016.
The idea of database scrambling is to replace all sensitive information with dummy data while keeping the full volume of records. A scrambled database could be used for different kinds of testing in all DTAP environments. This allows to test system on production scale and to reproduce all production bugs without breaking users' privacy.
What to scramble?
By sensitive information people usually mean:
- Marketing contacts (email, phone, post address) - to avoid leakage of marketing database to competitors
- Authentication and payments (logins, tokens, password hashes) - to avoid accounts hacking
- Personally identifiable information (full names, IP addresses) - to be compliant with GDPR rules about storing and processing personal info.
Scrambling pipeline
It is a good idea to use AWS CodeBuild as a CI tool for database scrambling. Because you can fine-tune its permissions with service role, and it allows long execution times. This way we could keep a build script - buildspec.yml, and scrambling SQL script in a project repository, allowing engineers to update it while the project grows.
The pipeline consists of: cloning production data to new cluster (1), adding a DB instance to cluster (2), generating new DB credentials (3), running scrambling SQL itself (4), deletion of DB instance (5), deletion of scrambling cluster with a final snapshot (6), sharing snapshot with another AWS account, where it's needed (7). Minimum execution time for the pipeline to start/stop databases is around 16 minutes.
Scrambling with SQL script
For example, you have a file scrambling.sql, which contains following statements to replace user emails with dummy data:
update users set email = concat('email', userId, '@example.com');
Then you can execute it on CodeBuild using following buildspec.yml:
build: commands: - echo "To be executed on host $DB_HOST" - mysql -vvv --host="$DB_HOST" -u "$DB_USERNAME" -p"$DB_PASSWORD" "$DB_NAME" -e "\. scrambling.sql"
Fast database copying with AWS Aurora
In the old days you had to make a dump, then restore dump on another server, which could take hours or even days. It's nice that AWS Aurora offers a feature to clone (copy) your database instantly. Internally it does not do any copying. Instead, it allows 2 database clusters to work with the same hard drive blocks. And when there is a write operation - it copies one block to existing DB and another - to new DB.

However, you still need to wait 7..10 min for a new database engine to start up. So, copying of any size DB is instant, but you can use it only after 7 min.
The following code sample of builspec.yml shows how you can clone Aurora database using AWS CLI:
pre_build: commands: - echo "Creating Aurora cluster for database scrambling" - aws rds restore-db-cluster-to-point-in-time --restore-type copy-on-write --use-latest-restorable-time --source-db-cluster-identifier "$CLUSTER_TO_COPY_FROM" --db-cluster-identifier "$NAME_FOR_NEW_CLUSTER" --db-subnet-group-name "$VPC_SUBNET" --vpc-security-group-ids "$VPC_SECURITY_GROUP" --db-cluster-parameter-group-name "$CLUSTER_PARAMETER_GROUP" --no-deletion-protection --kms-key-id "$KMS_KEY_FOR_NEW_CLUSTER" - echo "Creating instance in Aurora cluster" - aws rds create-db-instance --db-cluster-identifier "$NAME_FOR_NEW_CLUSTER" --db-instance-identifier "$NAME_FOR_NEW_INSTANCE" --db-instance-class db.r5.xlarge --engine aurora-mysql --db-parameter-group-name "$DB_PARAMETER_GROUP" - aws rds wait db-instance-available --db-instance-identifier "$NAME_FOR_NEW_INSTANCE" - echo "Cluster creation complete"
Five security levels
Security is an important aspect in database scrambling. If you do not implement it properly - whole concept of scrambling is gone.
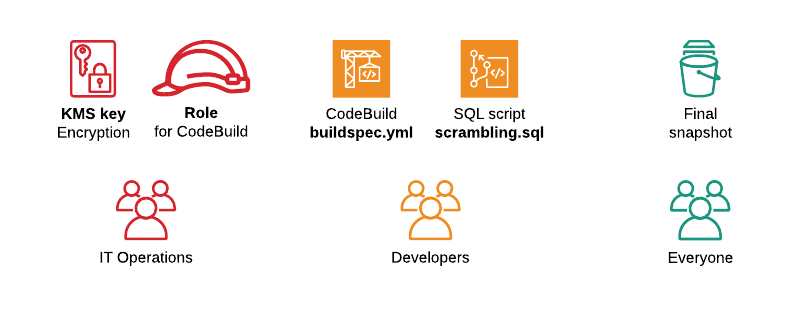
In our case security is ensured on 5 levels:
- Service role - permission for your CodeBuild job. It should have access to start and stop only a scrambling database, but not your production one. So, that even if you made some typo in build script - it can't damage your production.
- Database credentials - CodeBuild shouldn't have access to credentials of production DB. So, that if you accidentally try to scramble live database - it will fail due to wrong credentials. Instead, CodeBuild should generate new credentials for a newly created DB.
- Different AWS accounts. It's a good idea to do scrambling in one AWS account and then share a snapshot with another account. Multiple accounts simplify access control management within an organization.
- Encoding cluster and snapshots with KMS key. This way even you share a snapshot with somebody else, by mistake - they couldn't use it without access to the key.
- Code review. The last level of defense. Even if all levels above are applied, you are still able to do scrambling in a wrong way/ not fully. So, keeping buildspec.yml and scrambling.sql scripts in Git will enable traceability of changes. Make code review step required on your project - and risk human error will be minimized.
Conclusion
Cloud native services, like AWS Aurora, simplify working with big databases a lot. They take care of storage, make snapshots and restore them. This allows scrambling a big database of a few Tb during the night.
I have big experience in scrambling databases using AWS tools. Feel free to contact me if you need help or advice. And let's keep sensitive data away from humans!